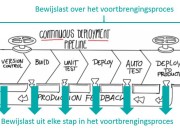
If you ask five experts to define Continuous Delivery, you’ll get six different answers. The responses will range from continuously merging code to a shared repository (i.e., Continuous Integration), to the use of modern delivery tools to manage discrete parts of the pipeline (e.g., provisioning, testing, and deployment), all the way up to delivering multiple releases per day to end users of an application.
But no matter how you define Continuous Delivery, the ultimate goal is to continually ship high-value software to your users. Unfortunately, many organizations are their own worst enemies in this regard.
Below are 4 common mistakes that organizations make when trying to do Continuous Delivery.
1. Focusing on development-centric processes instead of the whole release-to-production pipeline
But it works on my machine!
Ok, so we can still laugh at this timeworn sentiment—at least when it happens during demos at the end of a sprint. But it’s definitely NOT a laughing matter when a major glitch happens right before—or during—Production launch.
This mindset also might signal that the neither the Development team, nor the organization as a whole, is thinking about software delivery beyond the Continuous Integration stage.
For example, doing a deployment in a testing environment is completely different from deploying to Production. They may seem the same from a technical point of view, but from a process perspective, they are vastly different. Organizations that try to scale their Continuous Delivery implementation through build automation alone will have a hard time achieving success.
Why? Because delivering great software frequently—and at scale—requires adopting a holistic approach on the part of all stakeholders, one that takes into account that the entire pipeline, not just Development, must work as a well-tuned delivery system. A successful Production deployment requires much more than getting the code right in Development. Writing great code is important, but so is:
- Aligning Development efforts with other parties, like Marketing and Product Management, to understand whether what you’re developing is creating business value
- Integrating compliance into your pipeline to ensure that you’re adhering to regulations and keeping an audit trail
- Implementing proper security settings for the application in Production to protect your data and your customers
- Configuring and managing all operations activities needed to run software successfully in Production, such as changing firewall settings, configuring load balancers, and updating procedures and other paperwork
If your team is focused solely on improving the Continuous Integration side of Continuous Delivery without looking at the whole release pipeline, you will soon hit a wall.
2. Not aiming to deliver software daily
Your developers and product managers might not think that striving for delivery every day is important. They may be used to patterns of work such as hardening sprints, or delivering on a quarterly basis, but these habits can actually hold your team back.
Having a lot of work in parallel and only integrating code at the end of a quarter or a cycle means that merge and functionality conflicts won’t appear until late in the process when problems are harder to fix. While extensive hardening is necessary for verifying all differences, full integration every day or night will help you catch issues quickly. Doing so is vital to the quality of your system.
But more importantly—discovering problems early contributes to your learning cycle. If security vulnerabilities or code smell is introduced, it’s best to have a fast feedback loop to your developer. Integrating continuous testing that runs either daily or nightly will help you avoid making the same mistake twice.
From a cultural perspective, breaking through resistance to daily delivery is not the easiest thing to do. Deep organizational transformation is sometimes required, not only in engineering but also in other parts of the organization.
For example, if your Product Management team is used to two to four deliveries a year, switching to a model with smaller, more frequent deliveries can be really difficult. You have to transform your secondary processes to achieve a goal like this, processes for things like the yearly budgeting cycle, the appraisal and hiring system (which might be very rigid), risk management (which requires enormous effort) and keeping the control framework up to date. Simplifying these processes is hard, but to achieve faster delivery, it’s a necessity.
3. Focusing on the technical pipeline and tools, not the business result
It’s tempting to think that software delivery is all about technology and tools. Unfortunately, those who think this way tend to focus primarily on optimizing software development rather than on all the pieces that come before and after code has been written. As a result, they miss opportunities to maximize the value of that software to customers. Taking a technical approach to Continuous Delivery may be ok for a while, but it will not help you drive more value continuously.
Software delivery is first and foremost a business endeavor involving everyone in the pipeline from Design, Engineering, and Operations to Marketing and Sales. All the people, tools, tasks, and processes exist to drive business value. Harmonizing all these pieces requires expanding your approach to Continuous Delivery from development centered to business-value-streamcentered.
Your goal is to deliver value with your software, time after time. You can automate tasks, but unless business-focused orchestration is driving your pipeline, you won’t be able scale software delivery for your enterprise. Focusing only on the technical aspects of CI/CD will only get you so far. To truly succeed, you need to be laser-focused on the business value of each feature and how it is progressing through each stage in the pipeline.
4. Delaying integration, security, and performance testing until later in the cycle
Finding integration, security, and performance issues just before releasing software is much more expensive than if you catch these issues sooner. And they are harder to fix! That’s because these kinds of problems usually impact the code base much more substantially than functional problems do. Integration, security, and performance issues often require rethinking the architecture because they are deeply entangled with the system. Setting up a continuous feedback cycle to your developers is worth the hard work because it helps you catch these problems early.
Fortunately, release orchestration makes it easier to integrate security and performance testing into the pipeline so you can get immediate results and catch problems early. Xebialabs, for example, offers off-the-shelf integrations with testing tools, such as Sonar, Fortify, and Black Duck.
Security Testing
Security testing has four sides. Three of them, static code scanning, third-party library scanning, and dynamic security testing, can be embedded into, and therefore automated within, your Continuous Delivery pipeline.
The fourth side, penetration testing, most of the time requires a specific environment to deploy to because dynamic security testing frameworks can ruin your complete application. Because penetration testing requires human intervention, a good practice is to run these tests on a regular basis. Some organizations, for example, do them at the same time every day, or run them consistently on a monthly, quarterly, or yearly basis. Others follow a more risk-based approach, and judge whether, based on the impact of the new code, a penetration test is required.
Performance Testing
Running performance tests every night is a good practice. In particular, doing Load testing using data sets that are similar to those of your customers is extremely useful for determining whether the day’s changes impact performance in a good or bad way.
Running extensive performance tests over the weekend may also be useful because you can see how the system behaves under stress. Weekends are a good time to run these tests because it’s usually less disruptive to Development. Performance tests also require a real-world environment, preferably with a customer-like setup. This is crucial for getting good insight in the actual behavior of the system.
Conclusion
Avoiding these four common mistakes will drastically improve the outcome of your Continuous Delivery initiative. To recap:
- Delivering software is not just about Development and its build cycles—teams need to optimize the complete delivery pipeline.
- Fast feedback cycles are vitally important to have in place, so your team can find problems early in the cycle before they propagate and while they are cheaper to fix.
- Focus on the delivery of value to customers time after time. This approach requires teams to create a pipeline that is focused on the business benefit, not just the technology.
- Put an extensive nightly build and test cycle in place; it will help you continuously improve the quality of your software and learn what matters for customers, and what doesn’t.
In the end, it’s delivering value to customers… and collecting revenue from it… that really matter.
I’ve posted this article originally at blog.xebialabs.com.